"Viele glauben: Je größer das Modell, desto besser die Antworten. Die Wahrheit ist: Auch seine KI muss man Onboarden"
TL;DR: Retrieval-Augmented Generation (RAG) ist eine Technik, um Sprachmodellen (LLMs) zum Zeitpunkt einer Anfrage relevante Detailinformationen bereitzustellen. Dadurch können sie präzisere Antworten geben – ohne Halluzinationen und unabhängig vom Trainingszeitpunkt.
Das Grundproblem mit LLMs
LLMs können nur auf Informationen zugreifen, die bereits in ihren Trainingsdaten enthalten sind. Diese sind zeitlich begrenzt (Knowledge Cutoff) und oft veraltet. Werden sie nach Inhalten gefragt, die nicht im Training enthalten waren, erzeugen sie dennoch plausible, aber erfundene Antworten – sogenannte Halluzinationen.
Ein Workaround ist gezieltes Prompting: „Wenn die Antwort nicht im Kontext vorkommt, sage, dass du es nicht weißt.“ Aber: Woher bekommt das Modell den Kontext?
Antwort: RAG.
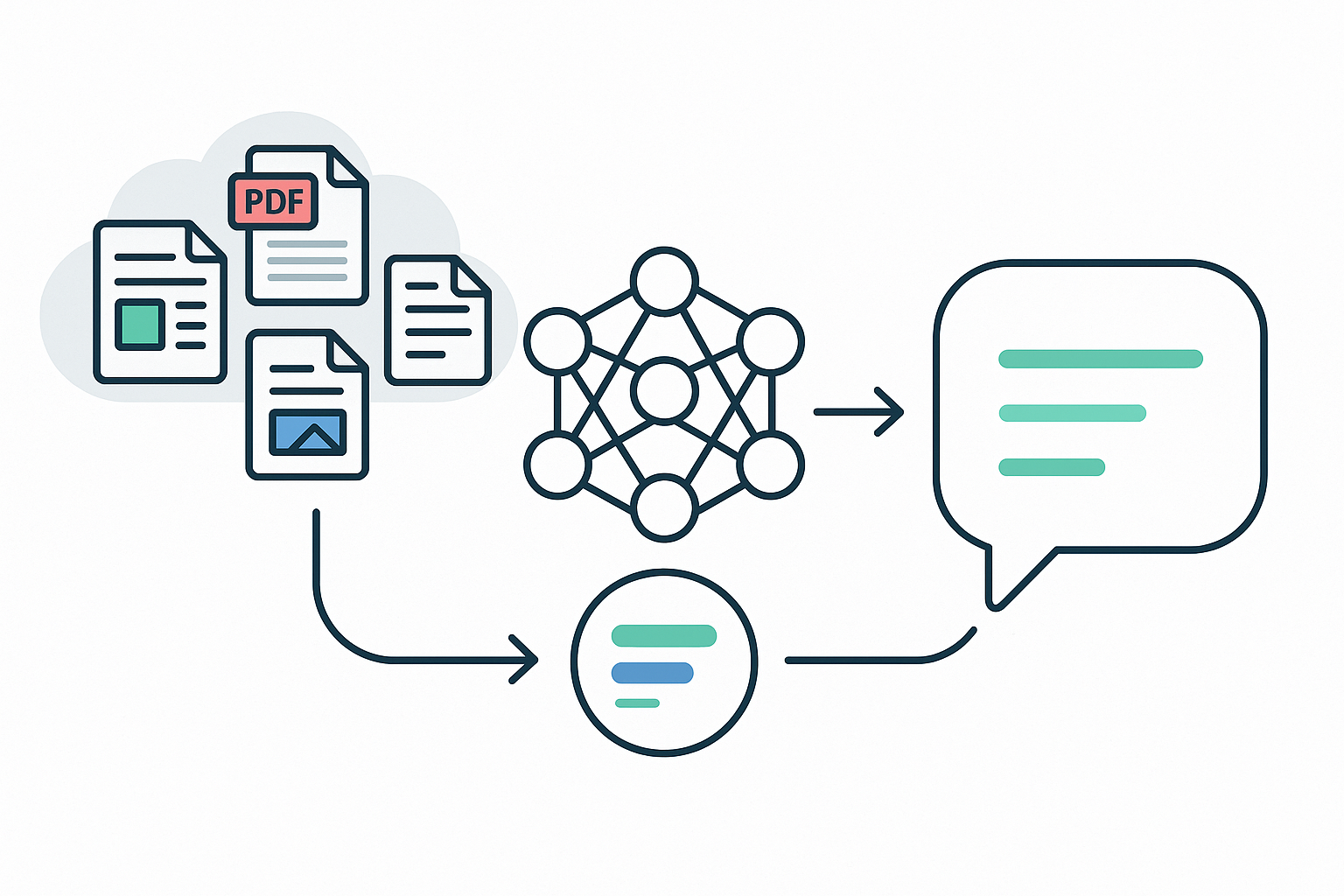
Wie funktioniert RAG?
1. Vorbereitung (Indexierung)
- Sammeln relevanter Daten: Dokumente, Knowledge Base, Webseiten, E-Mailverläufe
- Chunking: Daten werden in kleinere, semantisch sinnvolle Teile zerlegt (200–500 Tokens, mit Overlap). Dadurch bleibt der Kontext präzise.
- Embeddings: Jeder Chunk wird von einem Embedding-Modell in einen hochdimensionalen Vektor übersetzt (typisch 384–4096 Dimensionen). Diese Vektoren repräsentieren die semantische Bedeutung.
- Beispiel: „Auto“ und „Fahrzeug“ liegen eng beieinander, „Salat“ weit entfernt.
- Nähe wird meist über Cosine Similarity gemessen: kleiner Winkel → große inhaltliche Nähe.
- Speicherung: Vektoren + Chunks + Metadaten landen in einer Vektordatenbank (z. B. Qdrant, Pinecone).
2. Anfrage (Retrieval)
- Der Prompt bzw. die Kernfrage wird ebenfalls in einen Vektor übersetzt.
- Die Vektordatenbank sucht die ähnlichsten Vektoren und liefert die zugehörigen Textstücke.
- Diese Kontextinformationen werden gemeinsam mit dem Prompt an das LLM übergeben.
Warum ist das besser als nur GPT?
- Wiederholbare Ergebnisse – gleiche Fragen liefern gleiche Antworten.
- Präzise Informationen – nur vordefinierte, geprüfte Inhalte werden genutzt.
- Weniger Halluzinationen – das Modell kann „weiß ich nicht“ sagen.
- Quellenangaben – dank Metadaten können Originalquellen verlinkt werden.
- Modellunabhängigkeit – neue LLMs können genutzt werden, ohne die Daten neu zu trainieren.
Praxisbeispiele
- Kunden-Chatbot auf der Firmenwebsite mit Kenntnis aller relevanten Informationen
- Virtuelle Avatare - Frage an den Chef? Der virtuelle Doppelgänger hat immer Zeit
- Intelligente Knowledge Base für Mitarbeiter - Statt Teilinformation auf unterschiedlichen Seiten
- Kontext-Erweiterung für E-Mails oder CRM-Systeme - welche Lösung hat in ähnlichen Fällen bereits geholfen?
Wann ist RAG nicht ideal?
- Wenn es um reine Kreativaufgaben geht (Storytelling, Brainstorming).
- Bei sehr kleinen Datensätzen, die sich auch direkt in den Prompt einfügen lassen.
- Wenn Daten hochdynamisch und in Sekundenbruchteilen aktuell sein müssen (z. B. Börsenticker).
Fazit
RAG ist der Schlüssel, um KI-Systeme mit aktuellem, zuverlässigem Wissen zu versorgen – unabhängig vom Trainingsstand des Modells. Für Unternehmen bedeutet das: weniger Halluzinationen, verlässliche Antworten und die Möglichkeit, bestehende Wissensbestände intelligent zugänglich zu machen.